5 common mistakes with rel=canonical
Webmaster Stage: Intermediate to Advanced Together with a rel=canonical link in your webpage is a strong hint to search engines like google and yahoo your about most well-liked model to index amongst replica pages on the net. It’s supported by a couple of search engines like google and yahoo, together with Yahoo!, Bing, and Google. The rel=canonical hyperlink consolidates indexing houses from the duplicates, like their one-way links, as well as specifies which URL you’d like displayed in search results. However, rel=canonical is usually a bit difficult as a result of it’s no longer very obvious when there’s a misconfiguration.
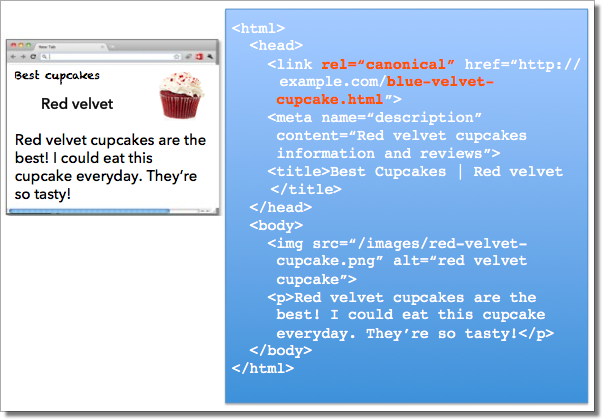 Whereas the webmaster sees the “purple velvet” page on the left in their browser, serps discover on the webmaster’s unintended “blue velvet” rel=canonical on the proper.
Whereas the webmaster sees the “purple velvet” page on the left in their browser, serps discover on the webmaster’s unintended “blue velvet” rel=canonical on the proper.We recommend the following easiest practices for the usage of rel=canonical:
- A big portion of the duplicate web page’s content will have to be existing on the canonical version.
- Double-check that your rel=canonical target exists (it’s no longer an error or “delicate 404”)
- Check the rel=canonical goal doesn’t incorporate a noindex robots meta tag
- Remember to’d want the rel=canonical URL to be displayed in search results (reasonably than the duplicate URL)
- Embrace the rel=canonical hyperlink in both the <head> of the page or the HTTP header
- Specify no multiple rel=canonical for a web page. When multiple is distinctive, all rel=canonicals might be unnoticed.
One test is to imagine you don’t have in mind the language of the content material—in case you placed the reproduction facet-by using-facet with the canonical, does an awfully large percentage of the words of the duplicate web page seem on the canonical page? If you want to speak the language to take into account that the pages are equivalent; as an example, if they’re best topically equivalent however no longer extraordinarily close in precise phrases, the canonical designation might be disregarded by way of engines like google.
Mistake 1: rel=canonical to the primary page of a paginated collection Think about that you have an editorial that spans a few pages:
- instance.com/article?story=cupcake-information&web page=1
- example.com/article?story=cupcake-information&page=2
- and so on
Specifying a rel=canonical from page 2 (or any later web page) to web page 1 isn’t right use of rel=canonical, as these will not be reproduction pages. The usage of rel=canonical in this instance would consequence within the content on pages 2 and beyond no longer being listed in any respect.
 Good content material (e.g., “cookies are superior nutrition” and “to vegetables”) is lost when specifying rel=canonical from element pages to the first page of a series.
Good content material (e.g., “cookies are superior nutrition” and “to vegetables”) is lost when specifying rel=canonical from element pages to the first page of a series.In instances of paginated content material, we recommend both a rel=canonical from element pages to a single-page version of the article, or to make use of rel=”prev” and rel=”next” pagination markup.
 rel=canonical from part pages to the view-all page
rel=canonical from part pages to the view-all page
 If rel=canonical to a view-all page isn’t certain, paginated content material can use rel=”prev” and rel=”next” markup.
If rel=canonical to a view-all page isn’t certain, paginated content material can use rel=”prev” and rel=”next” markup.Mistake 2: Absolute URLs mistakenly written as relative URLs

The <link> tag, like many HTML tags, accepts both relative and absolute URLs. Relative URLs embrace a route “relative” to the present page. For instance, “images/cupcake.png” means “from the present listing go to the “pictures” subdirectory, then to cupcake.png.” Absolute URLs specify the whole course—including the scheme like http://. Specifying <link rel=canonical href=“instance.com/cupcake.html” /> (a relative URL because there’s no “http://”) implies that the specified canonical URL is http://instance.com/example.com/cupcake.html despite the fact that that is almost under no circumstances what used to be meant. In these circumstances, our algorithms may ignore the required rel=canonical. In a roundabout way which means no matter you had hoped to accomplish with this rel=canonical will not come to fruition. Mistake three: Unintended or multiple declarations of rel=canonical Occasionally, we see rel=canonical designations that we believe are accidental. In very rare cases we see easy typos, but more regularly a busy webmaster copies a web page template without thinking to alter the goal of the rel=canonical. Now the website proprietor’s pages specify a rel=canonical to the template author’s site.
 In the event you use a template, test that you didn’t also copy the rel=canonical specification.
In the event you use a template, test that you didn’t also copy the rel=canonical specification.Every other problem is when pages include multiple rel=canonical links to different URLs. This occurs continuously along with SEO plugins that frequently insert a default rel=canonical link, possibly unbeknownst to the webmaster who installed the plugin. In instances of multiple declarations of rel=canonical, Google will likely ignore all the rel=canonical hints. Any merit that a legitimate rel=canonical might have supplied might be misplaced. In both all these circumstances, double-checking the web page’s source code will lend a hand proper the difficulty. Remember to take a look at your entire <head> part because the rel=canonical hyperlinks may be unfold aside.
 Check the behavior of plugins through taking a look at the page’s supply code.
Check the behavior of plugins through taking a look at the page’s supply code.Mistake four: Category or landing page specifies rel=canonical to a featured article Let’s say you run a web site about truffles. Your dessert web page has useful class pages like “pastry” and “gelato.” Every day the category pages feature a novel article. For instance, your pastry landing page might function “crimson velvet cupcakes.” Since the “pastry” category page has virtually all of the similar content as the “purple velvet cupcake” web page, you add a rel=canonical from the category page to the featured individual article. If we had been to just accept this rel=canonical, then your pastry category web page would not appear in search results. That’s since the rel=canonical indicators that you would prefer serps show the canonical URL instead of the replica. Alternatively, if you need customers so as to in finding both the category page and featured article, it’s best to only have a self-referential rel=canonical on the class web page, or none at all.
 Remember the fact that the canonical designation also implies the most popular show URL. Keep away from including a rel=canonical from a category or landing web page to a featured article.
Remember the fact that the canonical designation also implies the most popular show URL. Keep away from including a rel=canonical from a category or landing web page to a featured article.Mistake 5: rel=canonical in the <physique> The rel=canonical hyperlink tag should only appear in the <head> of an HTML document. Additionally, to steer clear of HTML parsing issues, it’s just right to include the rel=canonical as early as conceivable within the <head>. Once we stumble upon a rel=canonical designation in the <body>, it’s disregarded. This is a straightforward mistake to correct. Simply double-test that your rel=canonical links are at all times in the <head> of your page, and as early as that you can imagine if you can.
 rel=canonical designations within the <head> are processed, not the <body>.
rel=canonical designations within the <head> are processed, not the <body>.Conclusion To create valuable rel=canonical designations:
- Test that lots of the major text content of a duplicate page additionally seems in the canonical page.
- Test that rel=canonical is simplest specific once (if in any respect) and within the <head> of the page.
- Test that rel=canonical factors to an existent URL with excellent content (i.e., no longer a 404, or worse, a comfortable 404).
- Steer clear of specifying rel=canonical from landing or category pages to featured articles as so as to make the featured article the preferred URL in search results.
And, as at all times, please ask any questions in our Webmaster Help forum.
